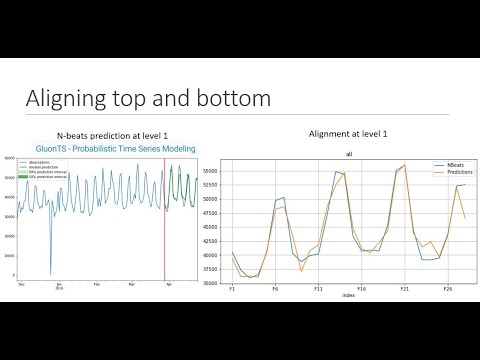
LLM inference optimization: Architecture, KV cache and Flash attention
YanAITalk
•
September 7, 2024

YanAITalk
View ChannelAbout
No channel description available.
Latest Posts

Upgrade Your EDC Today
AI-recommended products based on this video
Loading...

Victorinox Swiss Army Classic SD Pocket Knife, Camo
(45,533)
$33.00
$4.99 delivery Jun 19 - 25
Loading...
Victorinox Swiss Army Classic SD Pocket Knife, Camo
(45,533)
$33.00
$4.99 delivery Jun 19 - 25
Loading...

Rechargeable Flashlights High Lumens, KOOPER Super Bright Flash Light Pink, Small Zoomable LED Flashlight with 3 Lighting Modes, Portable Tactical Flashlight for Camping Essentials, Gift for Women
(322)
$21.59
FREE delivery Sun, Aug 10 on your first order
Loading...

Bark Shield- The BarkShield Pro, 2025 New Bark Shield Anti Barking Device for Dogs, with HD Display and LED Flashlight, with a Single Press, Attract Your Dog's Attention (Black-1pcs)
(0)
$28.95
FREE delivery Jun 19 - Jul 3
Loading...

The BarkShield Pro - Bark Shield Anti Barking Device for Dogs Bark Shield 100ft, Double Lights Flashing / 25000-40000 3-Speed Frequency Conversion, LED Flashlight
(0)
$21.98
$5.98 delivery Jul 2 - 22
Loading...

G5 Flashlight - G5 Rechargeable EDC Flashlight, G5 Pocket-Sized LED Light 400 Lumens, 180° Rotation Dual Light IP68 Waterproof Magnetic Mini Flashlight for Outdoor, Emergency & Daily Carry (Green)
(2)
$20.62$17.89
FREE delivery Jul 8 - 10
Loading...

Survival Multi-Tool with Fishing Tool, Fire Starter, Survival Whistle, Window Breaker,Bottle Opener for Everyday Carry Survival Gear Gifts for Men
(1,715)
$34.99
FREE delivery Thu, Jun 19 on your first order