Speculative Decoding: When Two LLMs are Faster than One


Efficient NLP
@efficientnlpAbout
Efficient NLP My name is Bai Li, I'm a machine learning engineer and PhD in natural language processing. Reach me at: Email: [email protected] LinkedIn: https://www.linkedin.com/in/libai/
Latest Posts



Video Description
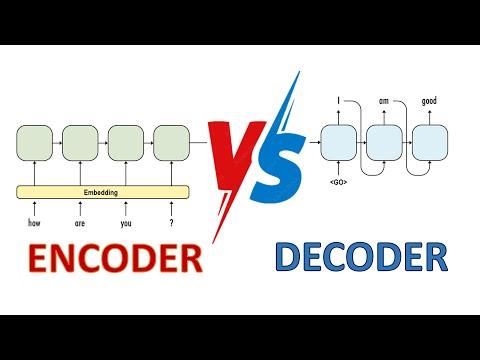
Try Voice Writer - speak your thoughts and let AI handle the grammar: https://voicewriter.io Speculative decoding (or speculative sampling) is a new technique where a smaller LLM (the draft model) generates the easier tokens which are then verified by a larger one (the target model). This make the generation faster computation without sacrificing accuracy. 0:00 - Introduction 1:00 - Main Ideas 2:27 - Algorithm 4:48 - Rejection Sampling 7:52 - Why sample (q(x) - p(x))+ 10:55 - Visualization and Results Deepmind Paper: https://arxiv.org/abs/2302.01318 Google Paper: https://arxiv.org/abs/2211.17192
You May Also Like












Boost Your NLP Setup
AI-recommended products based on this video

ELECROW 8 Inch Portable Monitor, 1280x800 Mini HD Display with Built-in Speakers, USB Powered, Non-Touch LCD Screen for Raspberry Pi, PC, Laptop, Jetson Nano, Game Consoles

Deeyaple USB C to Aux, 4FT/1.2M, Type C to 3.5mm Audio Cable Headphone Jack Cable for Car Mobile Phone, iPhone 16 15, iPad Pro, Samsung Galaxy S24 S23 S2010, Google Pixel,Oneplus Grey (1)

100W USB C Universal Laptop Charger Fit for Lenovo MacBook HP Dell Acer Asus Thinkpad Google MSI LG Samsung Huawei, ROG Ally, Steam Deck, Chromebook Computer and All USB-C Devices

INIU 45W Power Bank, Ultra Small 10000mAh Portable Charger, USB C in&Out Fast Charging Battery Pack, Travel External Phone Powerbank Compatible with iPhone 16 15 Samsung S25 S24 Google Pixel iPad etc

Car Carplay Woven Cable for iPhone 16 15 3.3FT USB A to USB C 3.2 Gen 2 Carplay Adapter Wire for iPhone 16 15 Pro Max, iPad Pro/Air, Samsung Galaxy S25/S24/S23/S22/S21 Google Pixel, Car Charger Cable

10.1 Inch Touch Portable Monitor IPS Screen 1366x768P 60Hz 400 Brightness 99% sRGB HDMI USB-C Monitors Switch for Xbox PS3/4/5 Laptop Compatible with Raspberry Pi, Mini Touch Screen
ELECROW 8 Inch Portable Monitor, 1280x800 Mini HD Display with Built-in Speakers, USB Powered, Non-Touch LCD Screen for Raspberry Pi, PC, Laptop, Jetson Nano, Game Consoles

7 Inch Portable Monitor Touchscreen HD 1024x600 LED Display Dual HDMI Port Small Monitor for PC Raspberry Pi Laptop Computer Xbox PS4/5 Switch Built-in Speakers

BrosTrend 1800Mbps WiFi 6 Linux WiFi Adapter for PC and Raspberry Pi 2+, Long Range USB WiFi Dongle Linux for Ubuntu, Mint, Debian, Kubuntu, Lubuntu, Zorin, Windows 11/10, Dual Band Wireless Antenna

GEEKOM IT13 2025 Mini PC 2025 Edition with 13th Gen Intel i9-13900HK, NUC 13 Mini Computers(14C/20T), 32GB RAM&1T M.2 2280 NVMe Gen4*4 SSD, Windows 11 Pro/Wi-Fi 6E/Bluetooth 5.2/USB 4.0/2.5G LAN
![Anker USB C Cable, [2-Pack, 6 ft] Type C Charger Premium Nylon USB Cable, USB A to Type C Charging Cable Fast Charge for Samsung Galaxy S10 S10+ / Note 8, LG V20 and Other USB C Charger (Black)](https://m.media-amazon.com/images/I/71N7xhCJnoL._AC_UL960_FMwebp_QL65_.jpg)
Anker USB C Cable, [2-Pack, 6 ft] Type C Charger Premium Nylon USB Cable, USB A to Type C Charging Cable Fast Charge for Samsung Galaxy S10 S10+ / Note 8, LG V20 and Other USB C Charger (Black)

Anker USB C Charger Cable (6ft 100W, 2Pack), USB 2.0 Type C Fast Charging Cable for iPhone 15 / 15Pro / 15Plus / 15ProMax MacBook Pro 2020, iPad Pro 2020, iPad Air 4, Samsung Galaxy S23+/S23 Ultra ClimatePartner certified

Anker Nano USB C Wall Charger,45W Fast Charging Smart Display Charger,with 180°Foldable Plug,Smart Recognition,Built-in Care Mode,for iPhone17/16/15 (Non-Battery,One USB-C Port,No Cable Included) ClimatePartner certified

Anker 332 USB-C Hub (5-in-1) with 4K HDMI Display, 5Gbps - and 2 5Gbps USB-A Data Ports and for MacBook Pro, MacBook Air, Dell XPS, Lenovo Thinkpad, HP Laptops and More

Corsair RM1000e Fully Modular Low-Noise ATX Power Supply - Dual EPS12V Connectors - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Modern Standby Support - Black

Corsair RM1200x Shift Fully Modular ATX Power Supply - Modular Side Interface - ATX 3.1 & PCIe 5.1 Compliant - Zero RPM Fan Mode - 105°C-Rated Capacitors - 80 Plus Gold Efficiency - Black, 1200W

Corsair RM1200e (2023) Fully Modular Low-Noise ATX Power Supply with 12V-2x6 Cable – ATX 3.1 & PCIe 5.1 Compliant, Cybenetics Platinum Efficiency, 105°C-Rated Capacitors, Modern Standby Mode – Black

Corsair HX1200i (2025) Fully Modular Ultra-Low Noise ATX Power Supply with 12V-2x6 Cable – ATX 3.1 & PCIe 5.1 Compliant, Cybenetics Platinum Efficiency, Fluid Dynamic Bearing Fan – Black

Beelink EQR5 Mini PC, AMD Ryzen 5 5650U(7nm, 6C/12T) up to 4.2GHz, Mini Computer 32GB DDR4 RAM 1TB PCIe3.0x4 SSD, Micro PC 4K@60Hz Dual HDMI Display/WiFi6/BT5.2/Office/Home/HTPC/W-11 Pro

BOSGAME Mini PC Intel Core i5 12600H(12C/16T, up 4.5GHz), 32GB DDR4 RAM 512GB PCIe SSD, Mini Desktop Computers Dual LAN/4x USB3.2/WiFi6E/BT5.2/HDMI+DP+USB-C/4K Triple Display
Beelink Mini PC, AMD Ryzen 7 5825U(6nm, 8C/16T) up to 4.5GHz, Mini Computer 32GB DDR4 RAM 500GB PCIe3.0x4 SSD, Micro PC 4K@60Hz Dual HDMI Display/WiFi6/BT5.2/Office/Home/HTPC/W-11 Pro

M9 Plus Mini PC with 2.1" Display, Intel Core i9-12900HK (14C/20T 5.0GHz), 32GB DDR4 RAM + 1TB NVMe SSD, Mini Desktop Computer, Compact Desktop Triple 4K Display, WiFi6, BT5.2, USB-C

Samsung 990 EVO Plus - 4TB PCIe Gen4. X4, Gen5. X2 NVMe 2.0 - M.2 Internal SSD, Speed Up to 7,250 MBs, Upgrade Storage for PC-Laptops, HMB Technology and Intelligent Turbowrite (MZ-V9S4T0B/AM)
![SAMSUNG 870 EVO SATA SSD 500GB 2.5” Internal Solid State Drive, Upgrade PC or Laptop Memory and Storage for IT Pros, Creators, Everyday Users, MZ-77E500B/AM [Canada Version]](https://m.media-amazon.com/images/I/911ujeCkGfL._AC_UL960_FMwebp_QL65_.jpg)
SAMSUNG 870 EVO SATA SSD 500GB 2.5” Internal Solid State Drive, Upgrade PC or Laptop Memory and Storage for IT Pros, Creators, Everyday Users, MZ-77E500B/AM [Canada Version]
![SAMSUNG 870 EVO SATA III SSD 4TB 2.5” Internal Solid State Drive, Upgrade PC or Laptop Memory and Storage for IT Pros, Creators, Everyday Users, MZ-77E4T0B/AM [Canada Version]](https://m.media-amazon.com/images/I/71W2nK7LUrL._AC_UL960_FMwebp_QL65_.jpg)
SAMSUNG 870 EVO SATA III SSD 4TB 2.5” Internal Solid State Drive, Upgrade PC or Laptop Memory and Storage for IT Pros, Creators, Everyday Users, MZ-77E4T0B/AM [Canada Version]
![SAMSUNG 990 PRO SSD 4TB PCIe Gen4 NVMe M.2 Internal Solid State Hard Drive, Up to 7,450MB/s, Heat Control, Direct Storage and Memory Expansion, MZ-V9P4T0B/AM [Canada Version]](https://m.media-amazon.com/images/I/81WuG6lQuDL._AC_UL960_FMwebp_QL65_.jpg)
SAMSUNG 990 PRO SSD 4TB PCIe Gen4 NVMe M.2 Internal Solid State Hard Drive, Up to 7,450MB/s, Heat Control, Direct Storage and Memory Expansion, MZ-V9P4T0B/AM [Canada Version]

LG UltraWide 34WP65C-B 34 Inch 21:9 Curved FreeSync 1ms 160 Hz WQHD(3440 x 1440) Gaming Monitor, Black

Lg gram 16-inch +View Portable Monitor with USB Type-C, DCI-P3 99% (Typ.), Auto Rotate, Two-Way Supported Folio Cover

StanbyME LG 27-Inch Class Smart Portable Touch Screen Monitor 27ART10AKPL. Built-in 3 Hour Battery, Full Swivel Rotation, Rollable. LG Stanbyme, Standbyme, Stand by me.

LG 24U411A-B 23.8" FHD (1920x1080) IPS Display Computer Monitor, 120Hz Refresh Rate, sRGB 99% (Typ.), USB-C, Reader Mode & Flicker Safe, Dynamic Action Sync, Black Stabilizer, Slim Stand Base, Black

Logitech M185 Wireless Mouse, 2.4GHz with USB Mini Receiver, 12-Month Battery Life, 1000 DPI Optical Tracking, Ambidextrous, Compatible with PC, Mac, Laptop - Black

Logitech G305 Lightspeed Wireless Gaming Mouse, Hero 12K Sensor, 12,000 DPI, Lightweight, 6 Programmable Buttons, 250h Battery Life, On-Board Memory, PC/Mac - Black

Logitech K400 Plus Wireless Touch TV Keyboard With Easy Media Control and Built-in Touchpad, HTPC Keyboard for PC-connected TV, Windows, Android, Chrome OS, Laptop, Tablet - Black
